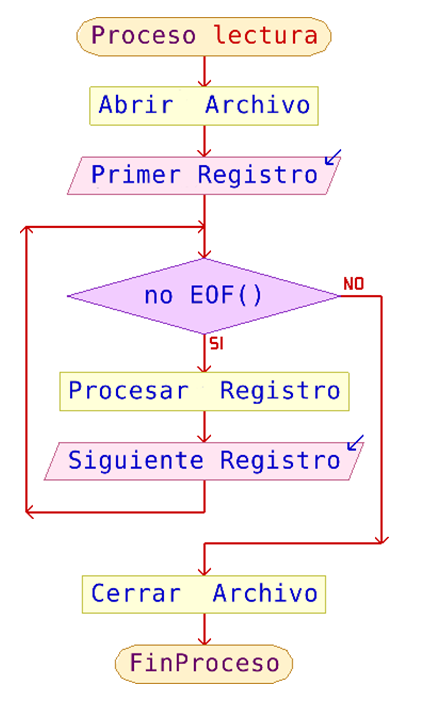
Pero cuando se lee secuencialmente un archivo siempre hay que procesar un registro tras otro hasta leer todo el archivo o hasta decidir si no se requieren más datos. Cuando se debe procesar el archivo completo, para detectar el final del archivo y no intentar leer datos inexistentes se utiliza una función que devolverá el estado de fin de archivo. La función que se utiliza en la mayoría de los lenguajes (y que utilizaremos en el pseudocódigo) es la sigla EOF() que corresponde a la palabra inglesa “end of file”, en castellano deberíamos utilizar algo como FDA() (Fin De Archivo) pero por costumbre seguiremos utilizando las sigla en inglés. Más adelante veremos un ejemplo de cómo utilizarla cuando veamos el proceso de lectura secuencial de un archivo.
Un detalle muy importante es que la función EOF() devuelve un valor verdadero cuando se trató de leer más allá del último registro, o sea, cuando la instrucción LEER trajo datos erróneos que no deberán ser procesados. Por lo tanto, el uso más acertado de la instrucción de lectura en el ciclo es posterior al proceso de datos.
Esto suena bastante confuso... ¿Se entiende con lo dicho en el párrafo anterior que debo procesar primero el registro y posteriormente leerlo? Es un absurdo, Lo que se debe entender es que al finalizar el proceso del registro en curso se debe leer el próximo registro a procesar, ahí el problema entonces estaría con el primer registro del archivo. Por eso siempre la primera lectura es antes de comenzar el ciclo de proceso de los datos del archivo.