Se denomina corte de control a un algoritmo típico en el proceso de datos que consiste en procesar un archivo que obligatoriamente debe estar ordenado por grupos de varios niveles para obtener totales por grupo.
Veamos un ejemplo: supongamos que tenemos un archivo que contiene una lista de personal de una empresa que tiene varias sucursales en todo el país, y que esta lista tiene los siguientes campos:
- Código de provincia
- Nombre de sucursal
- Cargo (1-encargado de sucursal, 2- administrativo, 3-operativo)
- Apellido y Nombres del empleado
- DNI del empleado
Supongamos que el archivo está ordenado primero por código de provincia, luego por Nombre de sucursal y por último está ordenado por cargo. Además, tenemos otro archivo cuyos registros contienen dos campos: código de provincia y nombre de provincia.
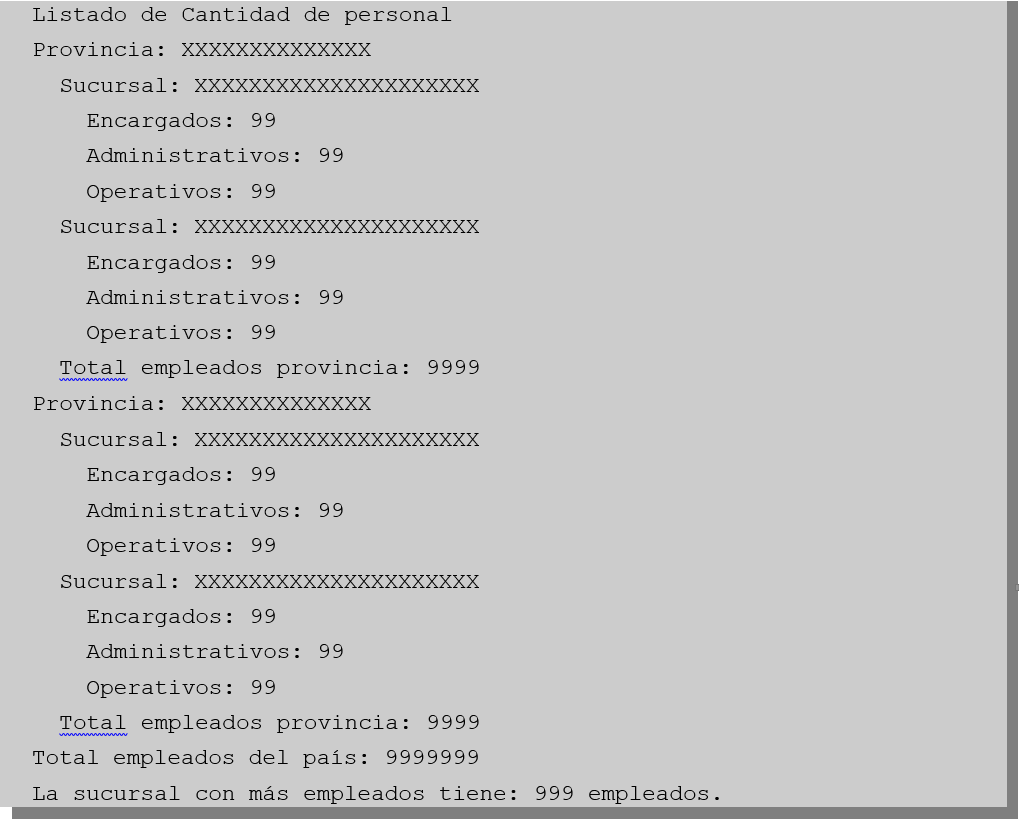
Queremos realizar un algoritmo que nos permita conocer cuántos empleados de cada tipo de cargo hay en cada sucursal. Cuantos empleados en total hay en cada provincia y cuántos empleados hay en total en todo el país. De paso, para complicar el algoritmo queremos saber cuántos empleados tiene la sucursal que más empleados tiene.
Digamos que por pantalla queremos que nos salga la información más o menos así:
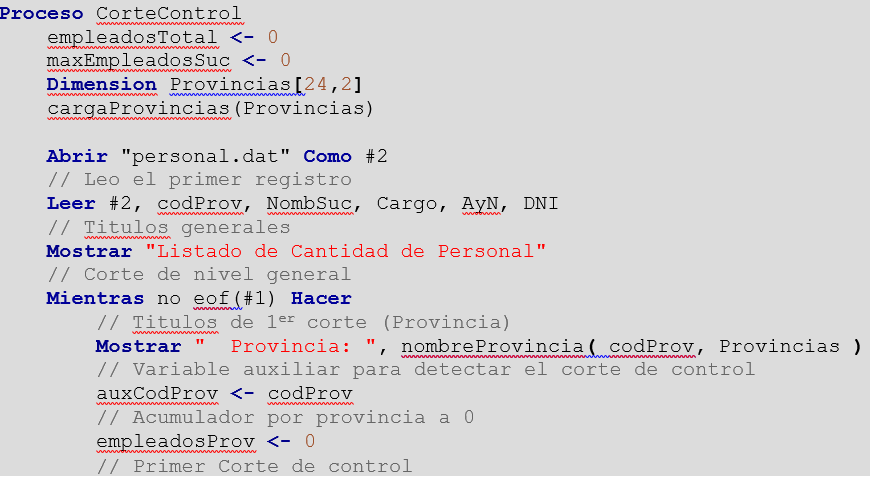
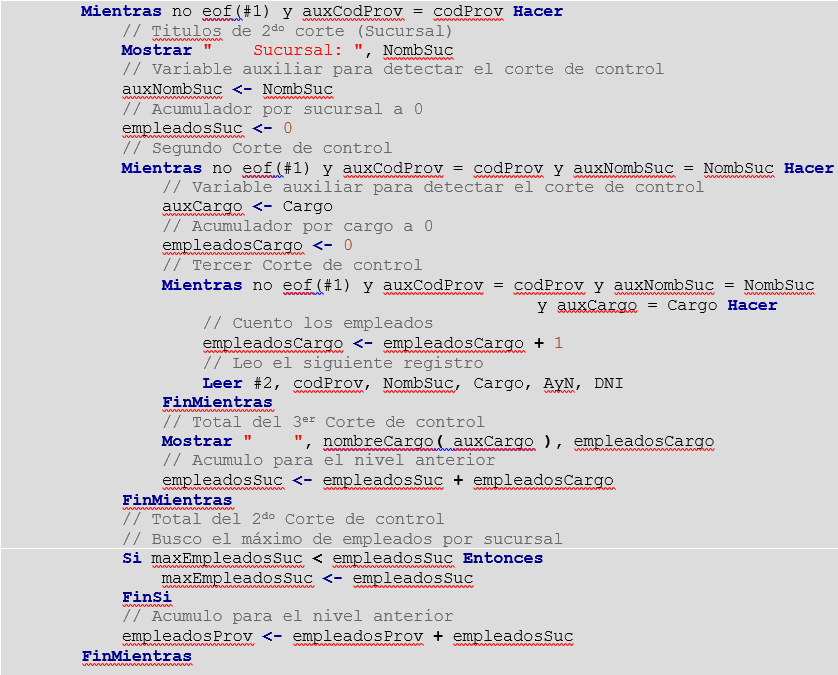
Un posible algoritmo para solucionar el problema sería :

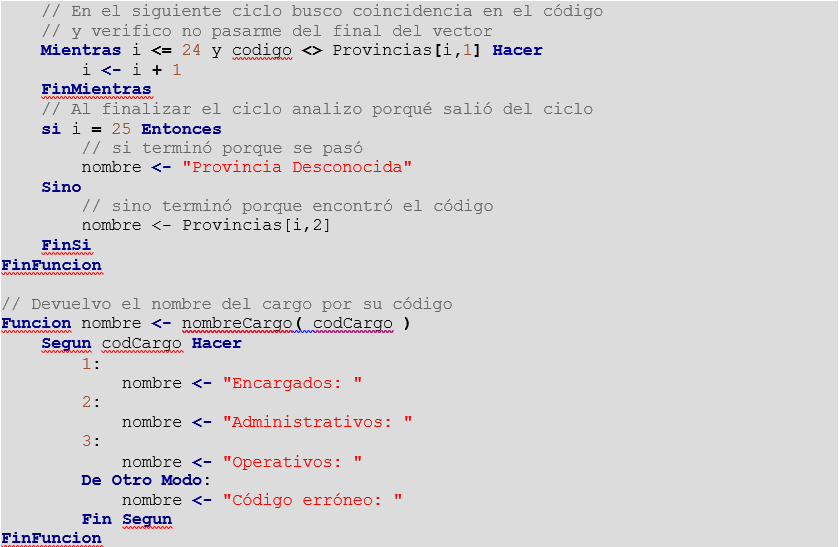
Si prestamos atención al algoritmo, hay dos campos que no han sido utilizados por el algoritmo, Apellido y Nombre y DNI del empleado. Sin embargo como estos datos están físicamente guardados en el archivo y ocupan lugar, deben ser leídos obligatoriamente para que el sistema controle el final del registro y no se pierda la sincronización de datos.